Control your robot with AI from the phosphobot dashboard
If you trained your model using phosphobot, you can control your robot directly from the phosphobot dashboard.You can fine tune the model in a single click from the dashboard. Go here to
learn how.
- Connect your robots and your cameras to your computer. Run the phosphobot server and go to the phosphobot dashboard in your browser: http://localhost
- Create a phospho account or log in by clicking on the Sign in button in the top right corner.
- (If not already done) Add your Hugging Face token in the Admin Settings tab with Write authorization. Read the full guide here.
- In the AI Training and Control section, enter the instruction you want to give the robot and click on Go to AI Control. Accept the disclaimer. You’ll be redirected to the AI Control page.
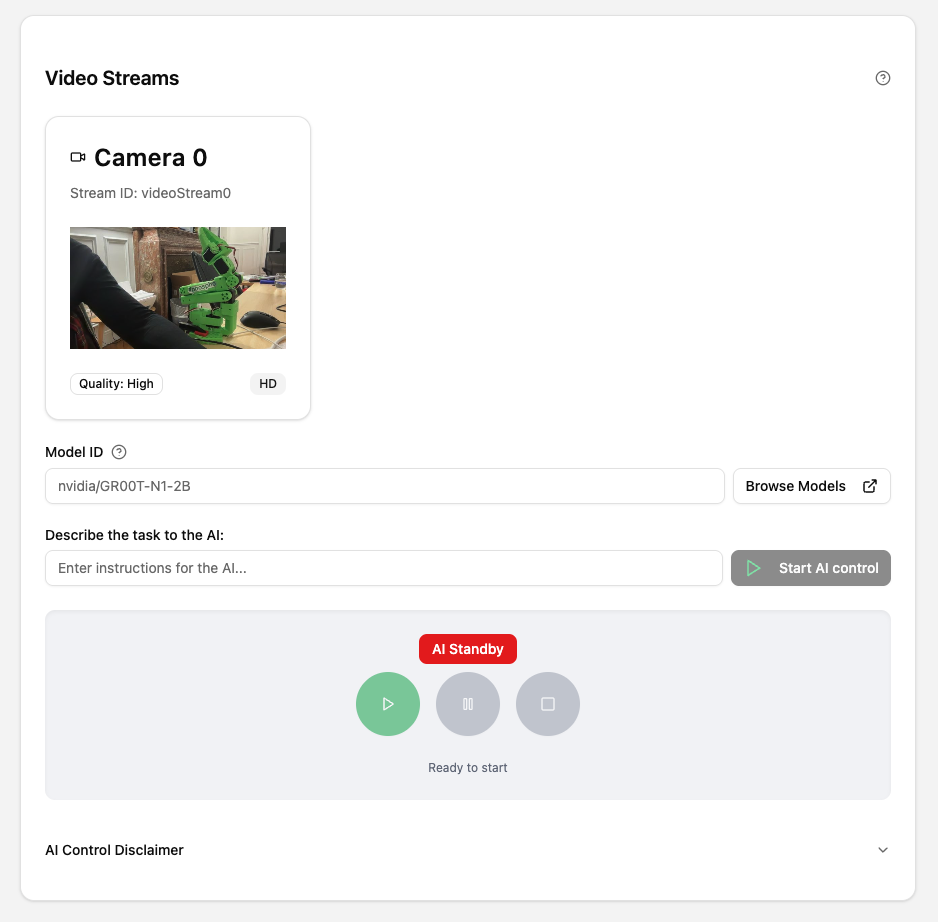
-
In the Model ID, enter the name of your model on Hugging Face (example:
phospho-app/YOUR_DATASET_NAME-A_RANDOM_ID). Double check the camera angles so that they match the ones you used to record the dataset. - Click on Start AI Control. Please wait: the first time, starting a GPU instance and loading the model can take up to 60 seconds. Then the robot will start moving.
Discord
Join the Discord to ask questions and share your demos!
How to control your robot with an AI model from a python script?
If you’re using a different model or want more fine-grained control, you can use thephosphobot python module to control your robot with an AI model.
1. Setup an inference server
First, you need to setup an inference server. This server runs on a beefy machine with a GPU that can run the AI model. It can be your own machine, a cloud server, or a dedicated server.If you choose a remote location, chose the closest location to minimize
latency.
Setup the inference server
How to setup the inference server?
2. Call your inference server from a python script
Open a terminal and run the phosphobot server.inference.py. Inside, copy the content of an example script below.
ACT
ACT
Example script for ACT
Pi0
Pi0
Example script for Pi0.5
gr00t-n1
gr00t-n1
Example script for gr00t-n1
You need to install thetorch and zmq libraries.What’s next?
Discord
Join the Discord to ask questions, get help from others and get updates (we
ship almost daily)
Policies
Learn more about Robotics AI models