What is the LeRobot Dataset Format?
The LeRobot Dataset format is a standard way to organize and store robot learning data, making it easy to use with tools like PyTorch and Hugging Face. You can load a dataset from the Hugging Face Hub or a local folder with a simple command likedataset = LeRobotDataset("lerobot/aloha_static_coffee"). Once loaded, you can access individual data frames (like dataset[0]) which provide observations and actions as PyTorch tensors, ready for your model.
A special feature of LeRobotDataset is delta_timestamps. Instead of just getting one frame, you can get multiple frames based on their time relationship to the frame you asked for. For example, delta_timestamps = {"observation.image": [-1, -0.5, -0.2, 0]} will give you the current frame and three previous frames (from 1 second, 0.5 seconds, and 0.2 seconds before). This is great for giving your model a sense of history. You can see more in the 1_load_lerobot_dataset.py example.
The format is designed to be flexible for different types of robot data, whether from simulations or real robots, focusing on camera images and robot states, but extendable to other sensor data.
How is a LeRobot Dataset Organized on Disk?
A LeRobot Dataset is organized on disk into specific folders for data (Parquet files), videos (MP4 files), and metadata (JSON/JSONL files). Here’s a typical structure for av2.1 dataset:
How to Manipulate and Edit LeRobot Datasets?
The common operations for manipulating and editing LeRobot datasets include:- Repairing: Fixing inconsistencies in metadata files (e.g.,
episodes.jsonl,info.json) or re-indexing episodes if files are added/removed manually. - Merging: Combining two or more LeRobot datasets into a single, larger dataset. This requires careful handling of episode indices, frame indices, task mappings, and recalculating or merging statistics.
- Splitting: Dividing a dataset into multiple smaller datasets (e.g., a training set and a test set). This also involves re-indexing and adjusting metadata and statistics for each new split.
phosphobot to perform common dataset operations.
How to Visualize a LeRobotDataset?
You can visualize a LeRobotDataset using the HuggingFace Visualize Dataset space, which leveragesrerun.io to display camera streams, robot states, and actions. This is a convenient way to inspect your data, check for anomalies, or simply understand the recorded behaviors.
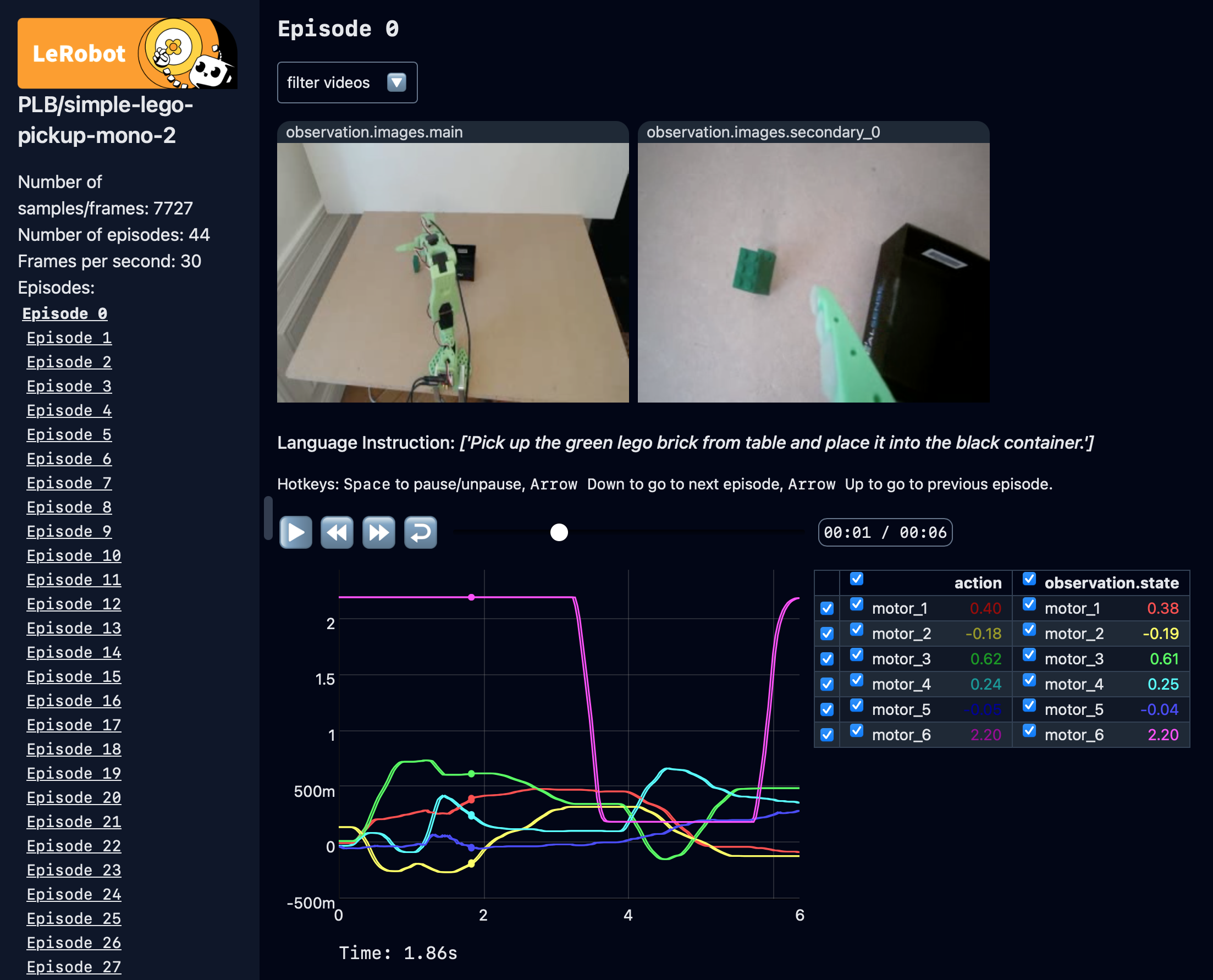
What are the columns in a LeRobot Dataset?
The core data in a LeRobot dataset consists of Parquet files containing trajectory information (like robot states and actions) and MP4 video files for camera observations.-
Parquet Files (
data/chunk-000/episode_xxxxxx.parquet):- These files store the step-by-step data for each robot episode.
- When loaded, this becomes part of a Hugging Face
Datasetobject (often namedhf_datasetin theLeRobotDatasetobject). - Common features you’ll find inside:
observation.state(list of numbers): Robot’s state, like joint angles or end-effector position.action(list of numbers): The action taken, like target joint angles.timestamp(number): Time in seconds from the start of the episode.episode_index(integer): ID for the episode.frame_index(integer): ID for the frame within its episode (starts at 0 for each episode).index(integer): A unique ID for the frame across the entire dataset.next.done(true/false, optional): True if this is the last frame of an episode.task_index(integer, optional): Links to a task intasks.jsonl.
-
Video Files (
videos/chunk-000/camera_key/episode_xxxxxx.mp4):- Camera images are stored as MP4 videos to save space.
- Each MP4 file is usually one camera’s view for one full episode.
- The
hf_dataset(when loaded) will point to these video frames using aVideoFrameobject for each camera observation (e.g.,observation.images.cam_high):VideoFrame = {'path': 'path/to/video.mp4', 'timestamp': time_in_video_seconds}.- The system uses this to grab the correct image from the video.
What Information is Stored in the LeRobot Metadata Files?
LeRobot metadata files, found in themeta/ directory, store crucial information about the dataset’s structure, content, statistics, and individual episodes.
-
info.json: Contains general information about the whole dataset.codebase_version(text): “v2.0” or “v2.1”. Tells you how to read other metadata, especially stats.robot_type(text): What kind of robot was used.fps(number): The intended frames-per-second of the data.total_episodes(integer): How many episodes are in the dataset.total_frames(integer): Total number of frames across all episodes.total_tasks(integer): Number of different tasks defined.total_videos(integer): Total number of video files.splits(dictionary): Info on data splits, like{"train": "0:N"}means episodes 0 to N-1 are for training.features(dictionary): Very important! This describes every piece of data: its type, shape, and sometimes names.- Example for
observation.state:{"dtype": "float32", "shape": [7], "names": ["joint1", ...]} - Example for a camera
observation.images.main:
- Example for
camera_keys(list of text, implied byfeatures): Names for camera data, likeobservation.images.main.
-
episodes.jsonl: A file where each line is a JSON object describing one episode.episode_index(integer): The episode’s ID.tasks(list of text): List of task descriptions (e.g., “pick up the red block”) for this episode.length(integer): Number of frames in this episode.
-
tasks.jsonl: A file where each line is a JSON object linking task IDs to descriptions.task_index(integer): The ID used in the Parquet files.task(text): The actual task description.
-
episodes_stats.jsonl(for v2.1): Each line is a JSON object with statistics for one episode.episode_index(integer): The episode ID.stats(dictionary): Contains stats ({'max': ..., 'min': ..., 'mean': ..., 'std': ...}) for each feature (likeobservation.state,action) within that specific episode.- For images, stats (mean, std) are usually per-channel.
-
stats.json(for v2.0): A single JSON file with statistics for the entire dataset combined.- Similar structure to the
statsobject inepisodes_stats.jsonl, but for all data.
- Similar structure to the
What are the Key Concepts and Important Fields in a LeRobot Dataset?
Key concepts in a LeRobot dataset include different types of indices (episode, frame, global), timestamps, and specific fields likeaction and observation.state which have precise meanings.
- Indices:
episode_index: Identifies an episode (e.g., 0, 1, 2…).frame_index: Identifies a frame within an episode (e.g., 0, 1, … up tolength-1). It resets for each new episode.index: A global, unique ID for a frame across the entire dataset. For example, if episode 0 has 100 frames (index 0-99), and episode 1 has 50 frames, episode 1’s frames would have global indices 100-149.
- Timestamps:
timestamp(in Parquet files): Time in seconds from the start of the current episode for that frame.VideoFrame.timestamp(for video features): Time in seconds within the MP4 video file where that specific frame is.fps(ininfo.json): The intended frame rate. Ideally,timestampshould be close toframe_index / fps.
actionfield: In robot learning, theactionrecorded at frametis usually the action that caused the observation at framet+1. For instance, if actions are target joint positions,action[t]might be the joint positions observed atobservation.state[t+1].observation.statevs.joints_position: The Python code example you saw might usejoints_positionfor joint angles andstatefor something else (like end-effector pose). LeRobot examples often useobservation.statemore broadly for the robot’s proprioceptive data (like joint positions). Always check the dataset’sinfo.json -> featuresto know exactly whatobservation.statemeans for that specific dataset.
What are Common Pitfalls and Best Practices for Working with LeRobot Datasets?
Common pitfalls when working with LeRobot datasets include version incompatibilities and memory issues, while best practices involve using version 2.1, understanding feature definitions, and ensuring data consistency.- Hugging Face Hub:
- LeRobot tools often use the
mainbranch on the Hub, but some datasets have their latest data on thev2.1branch. Make sure the training script references your correct dataset branch. - You’ll need a Hugging Face token with write access to upload or change datasets on the Hub.
- LeRobot tools often use the
- Local Cache: Datasets from the Hub usually download to
~/.cache/huggingface/lerobot. You can change this with therootargument when loading. Cache can lead to issue: sometimes, if you change a dataset on the Hub, your local cache might not update automatically. If this is the case, delete the local cache folder for that dataset to force a fresh download. - Version Choice: Strongly prefer
v2.1. It usesepisodes_stats.jsonl(per-episode stats), making it easier to manage and modify datasets (delete, merge, split, shuffle).v2.0(with a singlestats.json) is harder to keep correct if you change the dataset. delta_timestampsand History: This is great for temporal context but be aware that asking for a long history (many previous frames) means loading more data for each sample, which uses more memory and can be slower.- Feature Naming: Use the dot-notation like
observation.images.camera_nameorobservation.state. This is what LeRobot expects. - Data Consistency:
- Try to keep feature shapes (like the number of elements in
observation.stateor image sizes) the same, at least within an episode, and ideally across the whole dataset. If they vary, your code will need to handle it. fpsshould be consistent. If it varies,delta_timestampsmight not give you the time intervals you expect.
- Try to keep feature shapes (like the number of elements in
- Video Encoding: Videos are usually MP4, and only the avc1 codec is visible in the LeRobot dataset viewer. LeRobot uses torchvision to decode video. Details like codec are listed in
info.json. - Generating Statistics: If you make your own dataset, make sure the stats (
stats.jsonorepisodes_stats.jsonl) are correct. They are important for normalizing data during training. Thephosphobotcode has tools for this. episode_data_index: TheLeRobotDatasetcalculates this automatically when loaded. It helps quickly map global frame numbers to episode-specific frames, especially withdelta_timestamps.- Memory for Videos frames: Loading many high-resolution videos (from
delta_timestamps) can use a lot of memory. Choose video sizes that fit your needs and hardware. If you run into “Cuda out of memory” errors, lower the resolution of the videos. - Action Definition: Know exactly what
actionmeans in your dataset (e.g., target joint positions, joint velocities?). This is vital for training a policy. - Adding Custom Data: You can add your own observation or action types. Just make sure they can be turned into tensors and describe them in
info.json.
LeRobot Dataset Versions
LeRobot datasets have different versions (v1, v2, v2.1), withv2.1 being the recommended version for most use cases. The version is specified in the info.json file under the codebase_version field.
What are the Differences Between LeRobot v2.0 and v2.1 Dataset Versions?
The main differences between LeRobotv2.0 and v2.1 dataset versions lie in how they store statistics and support dataset modifications, with v2.1 being the recommended, more flexible version.
lerobot_v2.0(Older):- Uses one file,
meta/stats.json, to store statistics (like mean, min, max) for the entire dataset. - Modifying the dataset (like deleting an episode) is not well-supported with this version because updating these global statistics is tricky.
- Uses one file,
lerobot_v2.1(Recommended):- Uses
meta/episodes_stats.jsonlinstead ofstats.json. - This file stores statistics for each episode separately. Each line in the file is for one episode and its stats.
- This makes it much easier to manage the dataset, like deleting, merging, or splitting episodes, because stats can be updated or recalculated more easily for the affected parts.
- The
info.jsonfile will clearly statecodebase_version: "v2.1". - Recommendation: Always try to use or convert datasets to
v2.1for the best experience and support.
- Uses
phosphobot code, usually handles both versions, but v2.1 gives you more power.
What’s New in the Upcoming LeRobot v3.0 Dataset Format?
The upcoming LeRobot v3.0 dataset format introduces significant changes aimed at improving scalability, data organization, and efficiency, particularly for handling very large datasets. The primary rationale appears to be a move towards a more sharded and consolidated data structure, where episode data, videos, and metadata are grouped into larger, chunked files rather than per-episode files. This is evident from the conversion scriptconvert_dataset_v21_to_v30.py (from Pull Request #969 on GitHub), which details the transformation from v2.1 to v3.0.
Key Changes from v2.1 to v3.0:
-
Consolidation of Episode Data and Videos:
- Old (v2.1): Each episode had its own Parquet file (
data/chunk-000/episode_000000.parquet) and its own video file per camera (videos/chunk-000/CAMERA/episode_000000.mp4). - New (v3.0): Multiple episodes’ data will be concatenated into larger Parquet files (e.g.,
data/chunk-000/file_000.parquet). Similarly, videos from multiple episodes for a specific camera will be concatenated into larger video files (e.g.,videos/chunk-000/CAMERA/file_000.mp4).- The target size for these concatenated files seems to be configurable (e.g.,
DEFAULT_DATA_FILE_SIZE_IN_MB,DEFAULT_VIDEO_FILE_SIZE_IN_MB).
- The target size for these concatenated files seems to be configurable (e.g.,
- Old (v2.1): Each episode had its own Parquet file (
-
Restructuring of Metadata Files:
episodes.jsonl(Old v2.1): A single JSON Lines file where each line detailed an episode (episode_index,tasks,length).meta/episodes/chunk-000/episodes_000.parquet(New v3.0): This information, along with new indexing details (pointing to the specific chunk and file for data and video, andfrom/to_timestampfor video segments), will now be stored in sharded Parquet files. The schema will include columns likeepisode_index,video_chunk_index,video_file_index,data_chunk_index,data_file_index,tasks,length,dataset_from_index,dataset_to_index, and video timestamp information.tasks.jsonl(Old v2.1): A single JSON Lines file mappingtask_indextotaskdescription.meta/tasks/chunk-000/file_000.parquet(New v3.0): Task information will also be stored in sharded Parquet files (e.g., columnstask_index,task).episodes_stats.jsonl(Old v2.1): Per-episode statistics in a JSON Lines file.meta/episodes_stats/chunk-000/file_000.parquet(New v3.0): Per-episode statistics will also move to sharded Parquet files, likely containingepisode_indexand flattened statistics (mean, std, min, max for various features).
-
Updates to
meta/info.json:codebase_versionwill be updated to"v3.0".- Fields like
total_chunksandtotal_videos(which were aggregates) might be removed or rethought, as chunking is now more explicit. - New fields like
data_files_size_in_mbandvideo_files_size_in_mbwill specify the target sizes for the concatenated files. data_pathandvideo_pathwill reflect the newfile_xxx.parquet/mp4naming scheme.- FPS information will be added to features in
info["features"]if not already present in video-specific info.
-
Removal of
stats.json: The script explicitly mentions removing the deprecatedstats.json(which was already superseded byepisodes_stats.jsonlin v2.1). Global aggregated stats will now be computed from the sharded per-episode stats.
- Scalability for Large Datasets: The most significant driver appears to be improved handling of massive datasets (like DROID, mentioned in the PR diffs).
- Having fewer, larger files reduces filesystem overhead (e.g., inode limits) and can be more efficient for I/O operations, especially in distributed computing environments (like SLURM, also mentioned).
- Concatenating data into larger chunks makes sharding and parallel processing more manageable.
- Efficiency: Reading fewer, larger files can sometimes be faster than reading many small files.
- Standardization with Parquet for Metadata: Moving more metadata (episodes, tasks, episode_stats) into Parquet files brings consistency and allows leveraging the benefits of the Parquet format (columnar storage, compression, schema evolution) for metadata as well.
- Hub Management: The script includes steps for updating tags and cleaning up old file structures on the Hugging Face Hub, indicating a more robust versioning and deployment strategy.
LeRobotDataset abstraction.
What’s next?
Next, record your own dataset and use it to train a policy!Datasets
Recorde your first dataset
AI Training
Train your first AI model
Discord
Join the Discord to ask questions, get help from others and get updates (we ship almost daily)