What is a policy?
A policy is the brain of your robot. It tells the robot what to do in a given situation. Mathematically, it’s a function that maps the current state of the robot to an action .- the state is usually the position of the robot, the cameras and sensors feed, and the text instructions.
- the actions depends on the robot. For example, high level instructions (“move left”, “move right”), the 6-DOF (degrees of freedom) cartesian position (x, y, z, rx, ry, rz), the angles of the joints…
- the policy is basically the AI model that controls the robot. It can be as simple as a hard-coded rule or as complex as a deep neural network.
Old school robotics
Old school robotics
The traditional way to control robots is to use hard-coded rules.For example, you could write a program that tells the robot to move left when it sees a red ball. For that, you’d look for red pixels in the camera feed, and send a command to turn motor number 1 by 90 degrees if you see a cluster of red pixels.This approach is the one used in industrial robots and simple home robots. It’s simple and efficient, but it’s not very flexible. You need to write a new program for every new task.
Reinforcement Learning (RL)
Reinforcement Learning (RL)
Reinforcement Learning (RL) is another approach to train policies (since the 1990s and mainstream since the 2010s). In RL, the robot learns by interacting with the environment and receiving rewards. It’s like teaching a child to ride a bike by giving them feedback on their performance.Usually, the environment is a simulation. Today, it’s sucessful for walking robots that need to learn how to balance themselves.
Vision-Language Action Models (VLAs)
The latest paradigm since 2024 in AI robotics are Vision-Language Action Models (VLAs). They leverage Large Language Models (LLMs) to understand and act on human instructions.- VLA models are particularly well-suited for robotics because they function as a brain.
- VLA process both images and text instructions to predict the next action.
- VLA were trained using internet-scale data, so they have some common sense.
What are the latest architectures in AI robotics?
Since 2024, there have been breakthroughs in AI robotics. Here are some of the latest ideas in AI robotics.ACT (Action Chunking Transformer)
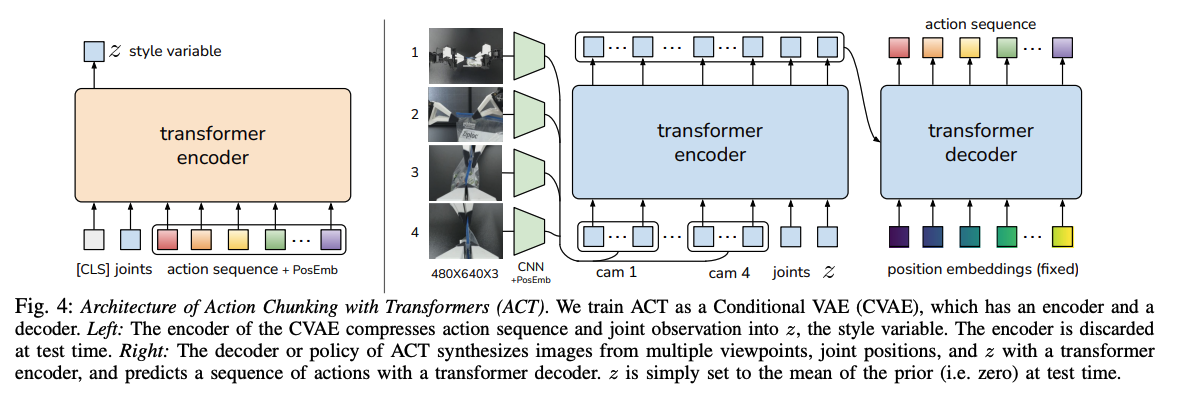
ACT (Action Chunking Transformer) (October 2024) is a popular repo that that showcases how to use transformers for robotics. The model is trained to predict the action sequences based on the current state of the robot and cameras’ images. ACT is an efficient way to do imitation learning. Learn more.Imitation Learning
Imitation Learning
Imitation Learning is a popular approach to train AI models for robotics. In imitation learning, the robot learns by mimicking human demonstrations. It’s like teaching a child to ride a bike by showing them how it’s done.Usually, the demonstrations are collected by teleoperating the robot. The robot learns to mimic the actions of the human operator. It’s mainly used for tasks that require human-like dexterity, such as picking up objects.
- You record episodes of your robot performing a task. (e.g., picking up a lego brick).
- The model learns from this data and enacts a policy based on it. (e.g., it will pick up the lego brick no matter where it is placed).
- Typically requires ~30 episodes for training
- Can run on an RTX 3000 series GPU in less than 30 minutes.
- This is a great starting point to get your hands dirty with AI in robotics.
- You don’t need prompts to train the model.
Train ACT with phospho
A few dozens of episodes are enough to train ACT to reproduce human demonstrations.
OpenVLA
OpenVLA (June 2024) is a great repo that showcases a more advanced model designed for complex robotics tasks. The architecture of OpenVLA include a Llama-2-7b model (July 2023) that receives a prompt describing the task. This gives the model some common sense and allows it to generalize to new tasks.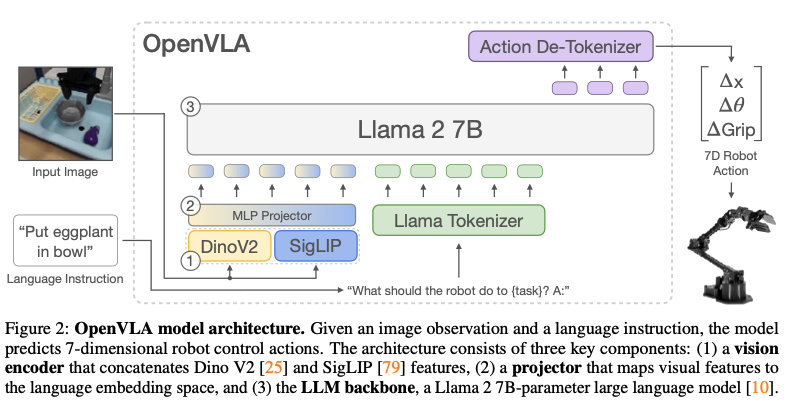
- Training such a model requires more data and computational power.
- Typically needs ~100 episodes for training
- Training takes a few hours on an NVIDIA A100 GPU.
Diffusion Transformers
Diffusion transformers are a family of models based on the diffusion process. Instead of deterministically mapping states to actions, the model hallucinates (generates) the most probable next action based on patterns learned from data. You can also see this as denoizing actions. This mechanism is common to many image generation models (e.g., DALL-E, Stable Diffusion, Midjourney…)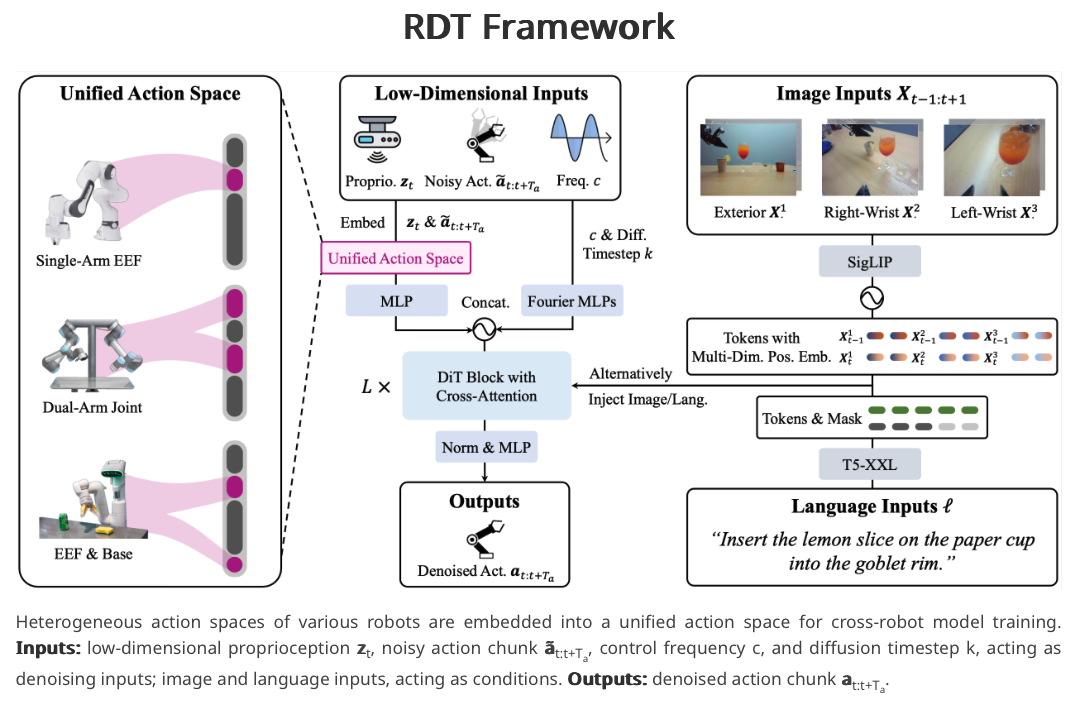
- The currently #1 model in robotics on Hugging Face is a diffusion transformer called RDT-1b (May 2024)
- Fine tuning the model on your own data is expensive but inference is fast.
What are the latest models in AI robotics?
Here are some of the latest models that combine ideas from ACT, OpenVLA, and Diffusion Transformers.gr00t-n1-2B and gr00t-n1.5-3B by Nvidia
GR00T-N1 (Generalist Robot 00 Technology) (March 2025) is NVIDIA’s foundation model for robots. It’s a performant models, trained on lots of data, which is ideal for fine tuning. The model weights are available on Hugging Face. GR00T-N1 combines both VLA for language understanding and Diffusion transformers for fine grained controls. For details, see their paper on arxiv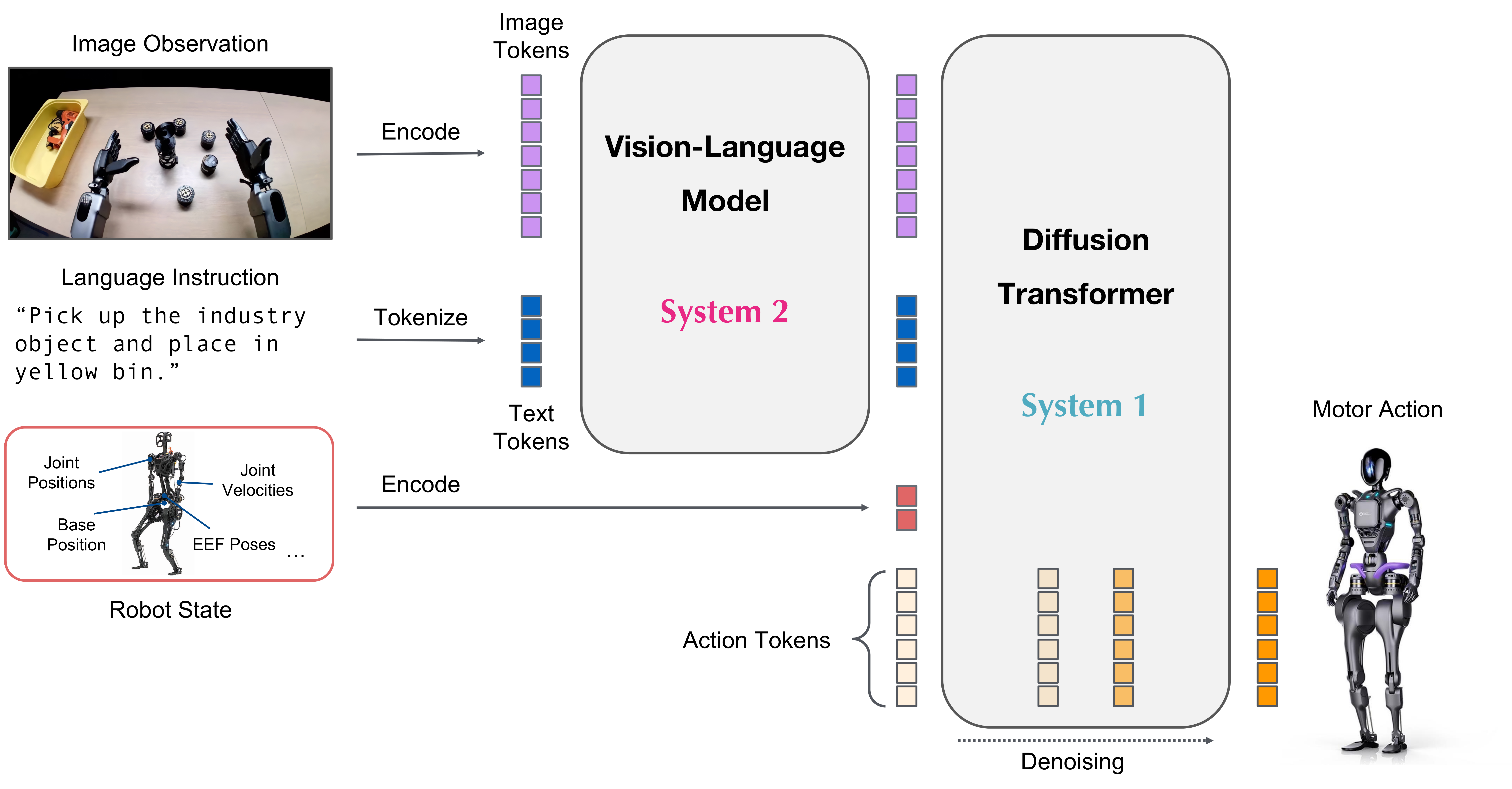
- Processes natural language instructions, camera feeds, and sensor data to generate actions.
- Based on denoizing of the action space, kind of like a Diffusion transformer.
- Trained on a massive datasets of human movements, 3D environments, and AI-generated data.
- Typically requires ~50 episodes for training.
- Supports prompting and zero-shot learning for tasks not explicitly seen during training.
- Small model size (2B parameters) for efficient fine-tuning and fast inference on Nvidia Jetson devices.
- The VLM is frozen during both pretraining and finetuning.
- The adapter MLP connecting the vision encoder to the LLM is simplified and adds layer normalization to both visual and text token embeddings input to the LLM.
Train gr00t-n1.5 with phospho
The gr00t-N1.5 model is a promptable model by NVIDIA
SmolVLA by Hugging Face
SmolVLA (June 2025) is a small, open-source Vision-Language-Action (VLA) model from Hugging Face designed to be efficient and accessible. It was created as a lightweight, reproducible, and performant alternative to large, proprietary models that often have high computational costs. The model, whose weights are available on Hugging Face, was trained entirely on publicly available, community-contributed datasets. It’s a 450M parameters model, trained with 30,000 hours of compute.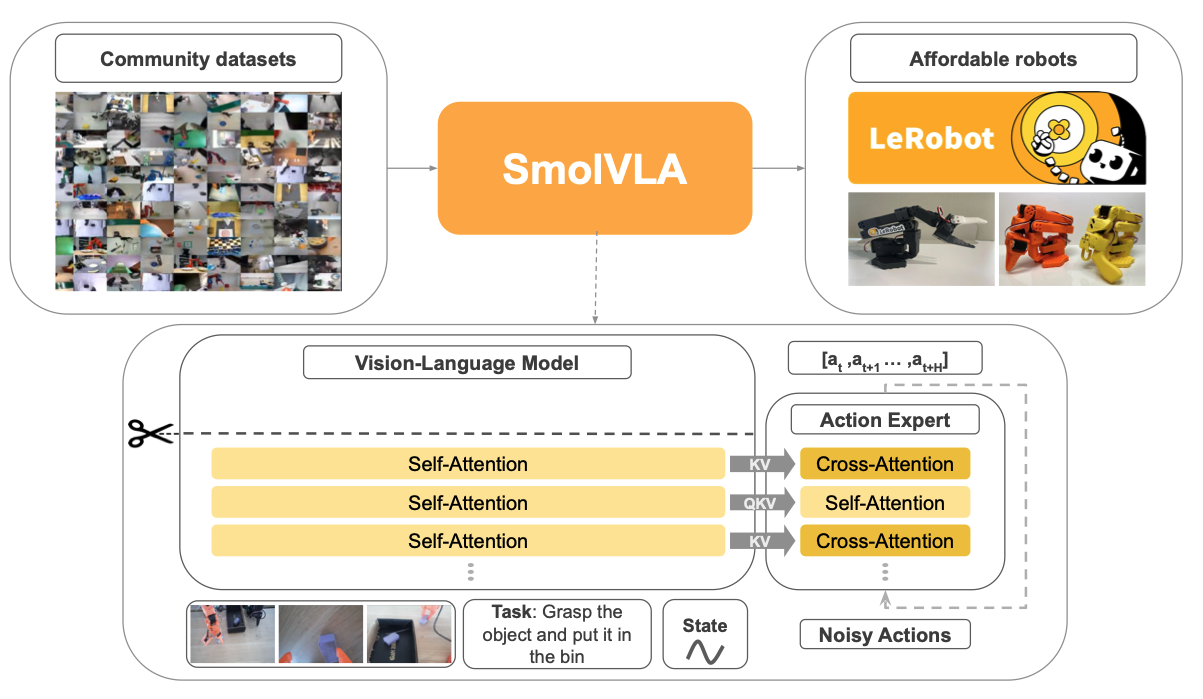
- SmolVLA has a modular architecture with two main parts: a vision-language model (a cut-out SmolVLM) that processes images and text, and an “action expert” that generates the robot’s next moves.
- The action expert is a compact transformer that uses a flow matching objective to predict a sequence of future actions in a non-autoregressive way.
- The model needs to be fine-tuned on a specific robot and task. Fine-tuning takes about 8 hours on a single NVIDIA A100 GPU.
Train SmolVLA with LeRobot
SmolVLA is an open-source model by LeRobot
pi0, pi-0 FAST, and pi0.5 by Physical Intelligence
pi0 (October 2024), also written as π₀ or pi zero, is a a flow-based diffusion vision-language-action model (VLA) by Physical Intelligence. The weight of pi0 are open sourced on Hugging Face. Learn more.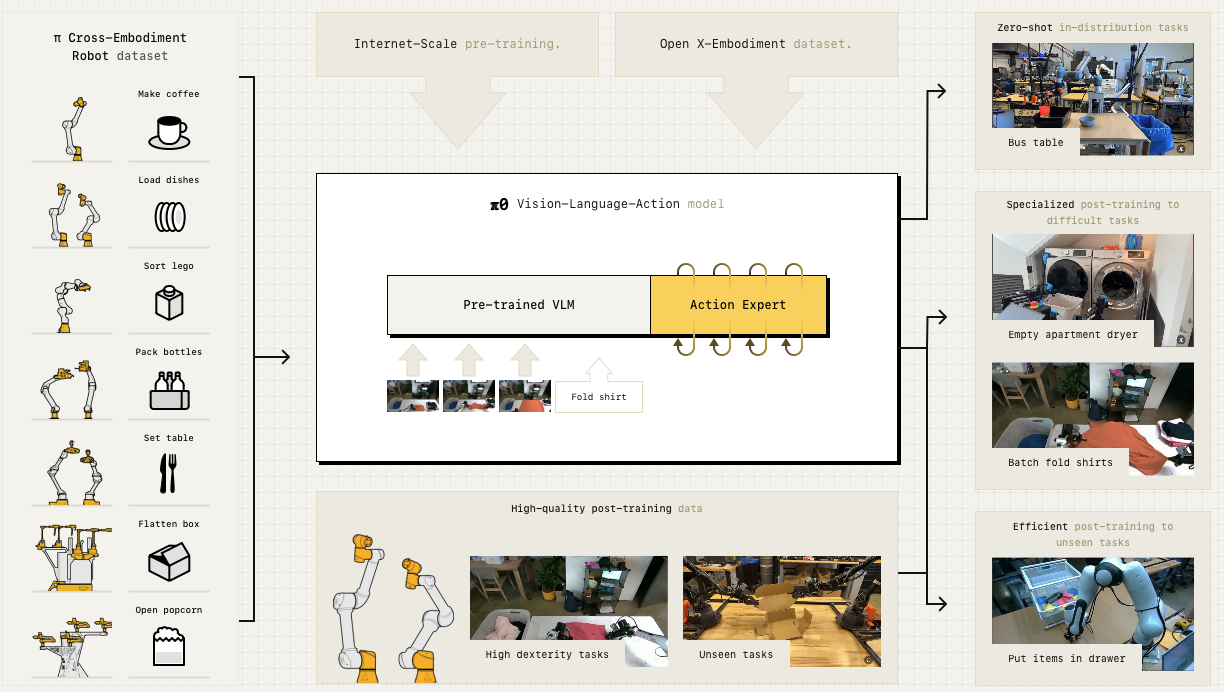
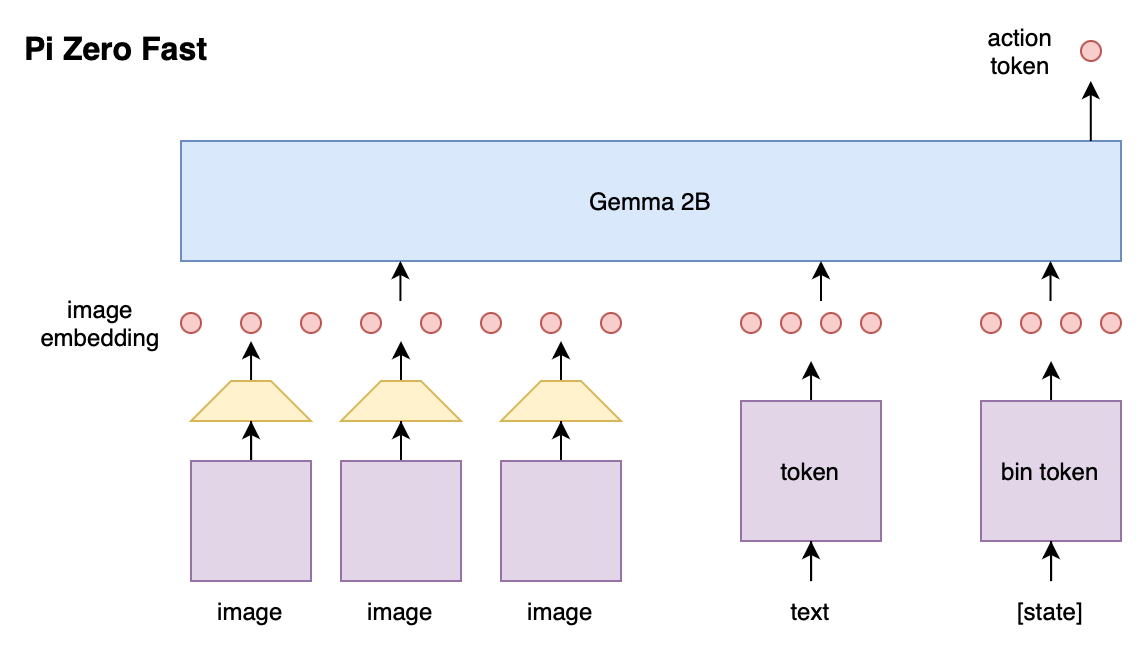

Train pi0.5 on phospho cloud
Head over to phospho cloud to start training pi0.5 on your own dataset.
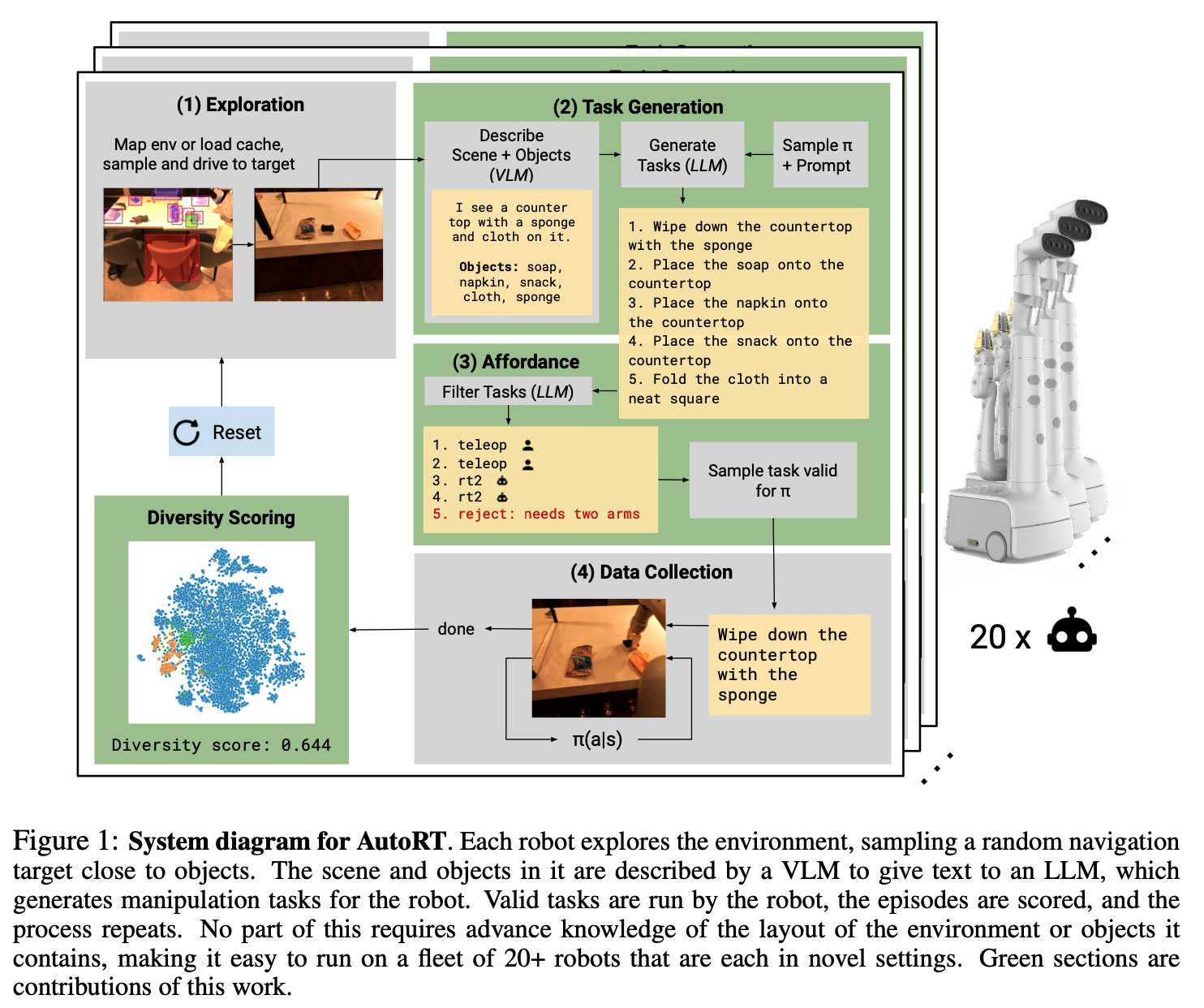
RT-2 and AutoRT by Google DeepMind
RT-2 (July 2023) is Google DeepMind’s twist on VLAs. It’s a closed-source model, very similar to OpenVLA. based on the Palm architecture. The model is trained on a large dataset of human demonstrations. Learn more.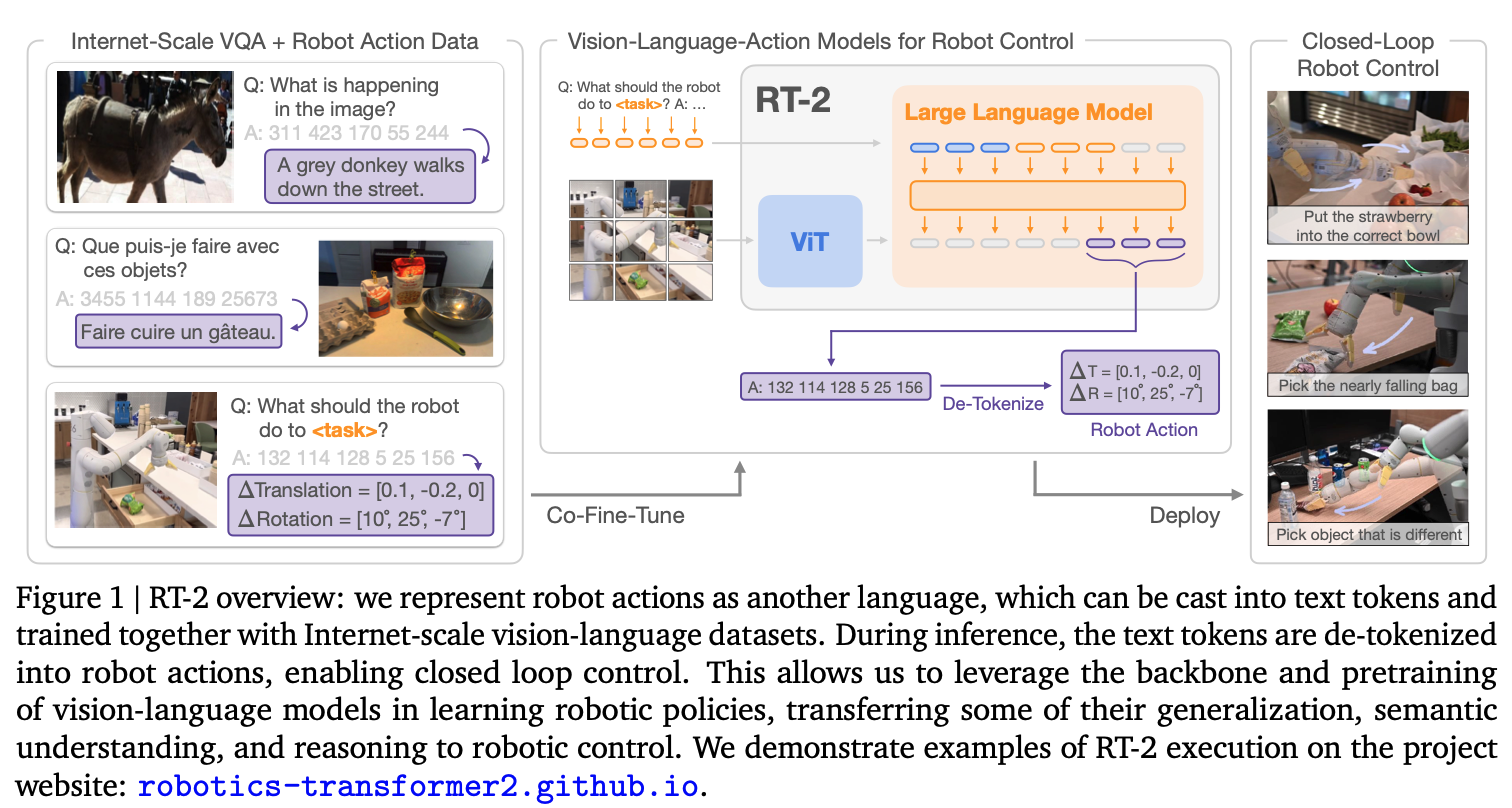
LeRobot Integration
LeRobot is a github repo by Hugging Face which implements training scripts for various policies in a standardized way. Supported policies include:- act
- diffusion
- pi0
- tdmpc (September 2022)
- vqbet (October 2023)